A high-performance C++ particle simulator leveraging multithreading (OpenMP & GCD), spatial partitioning (grid), SIMD (Apple Accelerate & auto-vectorization), and optimized memory patterns for real-time physics simulation.
ParticleBox is a high-performance C++ physics simulator capable of rendering thousands of interacting particles in real-time. It leverages modern C++17 features, SIMD acceleration (Apple Accelerate), and multithreading (OpenMP/GCD) to maximize throughput on multi-core systems.

To maintain performance, we calculate squared distances to avoid expensive square root operations in the inner loop:
\[ d^2 = (p2.x - p1.x)^2 + (p2.y - p1.y)^2 \]
A collision occurs when \(d^2 < (r1 + r2)^2\). For force calculations requiring normalized vectors, we employ the Fast Inverse Square Root algorithm.
Repulsion forces are applied proportional to the overlap depth \(\delta\):
\[ \mathbf{F}_r = -\hat{\mathbf{n}} \cdot \text{repulsionStrength} \cdot \delta \]
State updates are handled via Semi-Implicit Euler integration for stability and speed:
\[ \mathbf{v}_{t+\Delta t} = \mathbf{v}_t + (\mathbf{F}_t / m) \cdot \Delta t \] \[ \mathbf{p}_{t+\Delta t} = \mathbf{p}_t + \mathbf{v}_{t+\Delta t} \cdot \Delta t \]
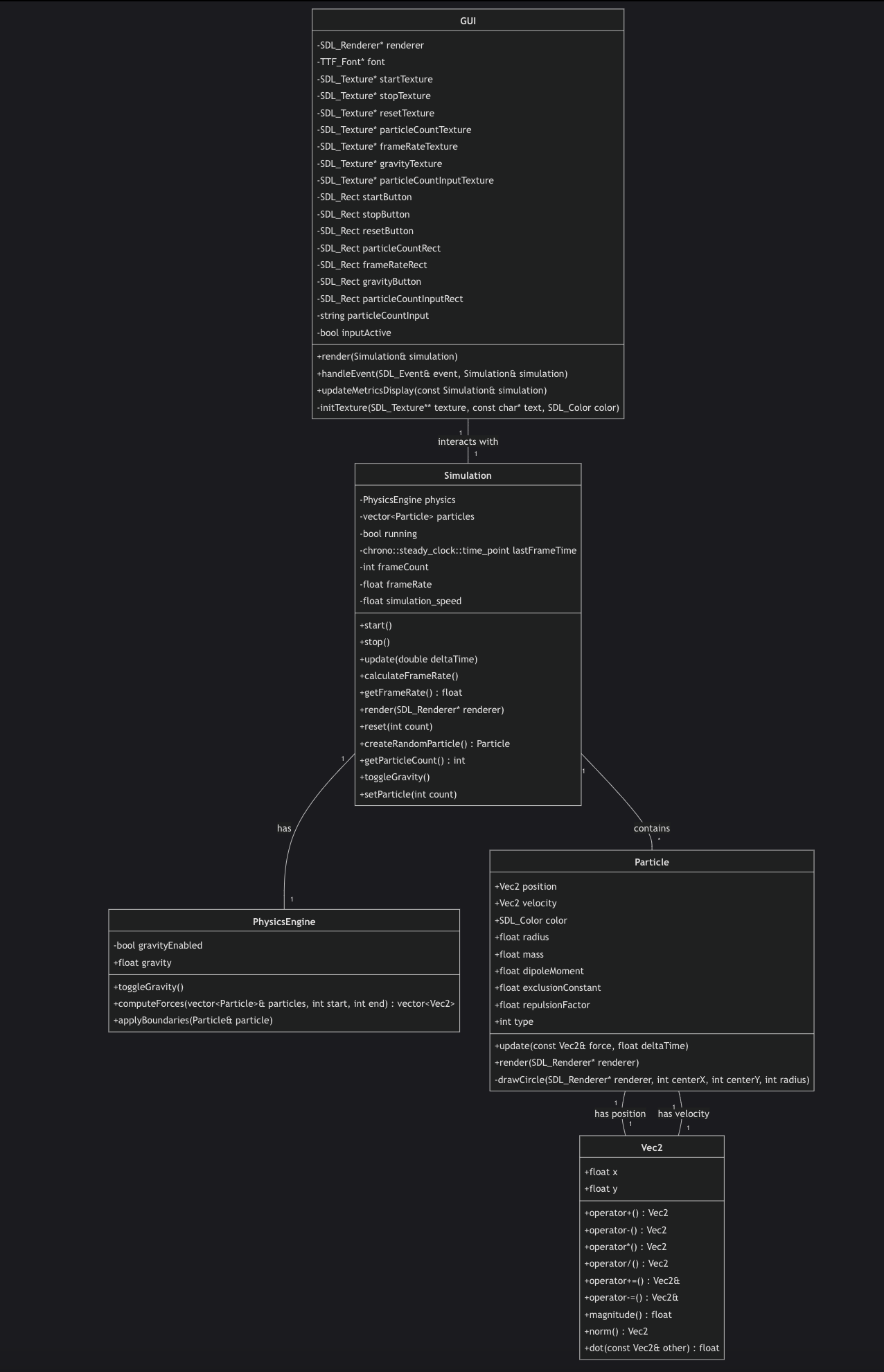
The codebase is structured for modularity and performance:
The grid system uses a flat-array structure to optimize neighbor lookups. Particles are mapped to cells using bitwise spatial hashing, allowing for constant-time access to potential collision candidates.
The engine implements a platform-agnostic threading model:
std::async fallbacks for Windows/Linux
environments.
Vector operations are accelerated using simd_float2 on macOS, while
std::vector pre-allocation prevents runtime resizing. Data is stored in an Array of Structs
(AoS) pattern, optimized for the specific access patterns of the simulation loop.
Profiling with Instruments and VTune guided the optimization process, resulting in:
-O3, -march=native, -mcpu=apple-m1,
-ftree-vectorize, -fopenmp).
std::async,
std::future), Apple Grand Central Dispatch (GCD)
simd/simd.h), Compiler
Auto-Vectorization (via flags)